上一篇讲了 ptmalloc 在初始化的过程中做的一些准备工作 主要是内存的申请,这里主要是基于初始化的数据格式对内存进行分配、回收管理。重点是 各种 bin的使用,其如同缓存 减少程序频繁的内存申请操作 对内核的调用(毕竟需要且到内核态执行代码)。
1.0 _int_malloc 代码结构 函数 _int_malloc 的代码量很大,代码逻辑主要是基于 bins (fastbin smallbin largebin unsortedbin)查找合适的chunk,这里将函数 _int_malloc 中的代码分成多个部分分析,整个代码结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static void * _int_malloc (mstate av, size_t bytes) { // 将用户请求的内存尺寸以 16byte 向上对齐 checked_request2size (bytes, nb); if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ())) { // #1.1 如果用户请求尺寸是在 fast bin 的尺寸范围 则在 fastbin 链表中找合适的chunk 并将地址返回给用户 } if (in_smallbin_range (nb)) { // #1.2 如果用户请求尺寸是在 small bin 的尺寸范围 则在 fastbin 链表中找合适的chunk 并将地址返回给用户 } else { // #1.3 如果用户请求尺寸是在 large bin 的尺寸范围 则调用函数 malloc_consolidate 对chunk进行处理 idx = largebin_index (nb); if (atomic_load_relaxed (&av->have_fastchunks)) malloc_consolidate (av); } for (;; ) { int iters = 0; while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av)) { // #2.1 在 unsort bin 的链表中查找合适尺寸的chunk 找到的话将内存地址返回给用户 } if (!in_smallbin_range (nb)) { // #2.2 在large bin 中查找比用户请求尺寸大的 chunk ,找到后讲其切割,用户尺寸部分返回给用户 剩下的内存尺寸给 remainder_chunk } // ...... for (;; ) { // #2.3 从整个bin里面查找,这里查找使用了 bitmap 他记录了所有的空闲bin 方便查找 } use_top: // #2.4 整个bin里面都没有找到合适的chunk 就要对 top chunk 进行切割,切割下来的返回给用户,剩下的还是 top chunk } }
首先是对用户申请内存尺寸对齐计算的宏 checked_request2size ,这里涉及到多个宏,具体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #define INTERNAL_SIZE_T size_t // unsigned long #define SIZE_SZ (sizeof (INTERNAL_SIZE_T)) // 在x64 架构上是 8 // malloc 对齐尺寸 在 x64 上 这里是 2 * 8 = 16 byte #define MALLOC_ALIGNMENT (2 * SIZE_SZ < __alignof__ (long double) ? __alignof__ (long double) : 2 * SIZE_SZ) // malloc_chunk 偏移到 属性 fd_nextsize 需要移动的位置是 4 * 8 = 32 byte #define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize)) // 掩码 对齐值减一作为掩码是对齐计算中常用的方法 还要结合取反 #define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1) // 最小尺寸 是需要与 MALLOC_ALIGN_MASK 对齐 也就是 32 byte #define MINSIZE (unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)) // 这里就是将 req 以 16字节向上对齐 req + SIZE_SZ ? #define request2size(req) (((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? MINSIZE : ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK) // 用户申请的内存最大值不能超过的范围 ? -1 * MINSIZE 能明白 但为什么是 -2 呢 #define REQUEST_OUT_OF_RANGE(req) ((unsigned long) (req) >= (unsigned long) (INTERNAL_SIZE_T) (-2 * MINSIZE)) // 处理用户申请的内存尺寸 并判断内存尺寸是否在允许范围内 #define checked_request2size(req, sz) ({ (sz) = request2size (req); if (((sz) < (req)) || REQUEST_OUT_OF_RANGE (sz)) { __set_errno (ENOMEM); return 0; } })
然后是一个判断,如果进程当前通过锁没有抢占到 arena 这里通过函数 sysmalloc 去申请
1 2 3 4 5 if (__glibc_unlikely (av == NULL)) { void *p = sysmalloc (nb, av); if (p != NULL) alloc_perturb (p, bytes); return p; }
2 快速直接的查询chunk malloc 会尝试先查找合适的chunk 这些chunk会被缓存到各个 bin中,这里先在 fast bin 与 small bin 中进行查询,找到则返回 找不到进入到下一步的处理
2.1 在 fast bin 上查询合适的chunk 代码里使用的宏比较多,这里先展开宏 便于后面代码分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #define REMOVE_FB(fb, victim, pp) do { victim = pp; if (victim == NULL) break; } while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) != victim); // idx = sz / 2^4 - 2 = sz / 16 - 2 sz 最小值是 MINSIZE 32 byte 当然 这个值是在 x64 系统上 #define fastbin_index(sz) ((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2) // 读取arena 对应索引的chunk #define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx]) // 类似掩码码的作用 00....111 #define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA) #define chunksize_nomask(p) ((p)->mchunk_size) // 通过掩码将 mchunk_size 底三位设置为 0 ,然后得出 chunk的真实大小 #define chunksize(p) (chunksize_nomask (p) & ~(SIZE_BITS)) // 往后偏移两个 chunk成员属性的位置 #define chunk2mem(p) ((void*)((char*)(p) + 2*SIZE_SZ)) // 往前偏移两个 chunk成员属性的位置 也就是 回到 chunk 内存起始位置 #define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ))
基于 fast bin 查询 chunk
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 // 如果用户请求的尺寸在 fast bin 的缓存范围内,get_max_fast获取的值是 在 malloc_init_state 中设置的 if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ())) { // 根据 尺寸计算出 对应在 fastbin 链表中的索引位置 idx idx = fastbin_index (nb); // 读取chunk 这里使用的是地址的地址 方便下面移动fd指针的时候 就将 victim 从链表中移除 mfastbinptr *fb = &fastbin (av, idx); mchunkptr pp; victim = *fb; if (victim != NULL) { // 条件成功 说明victim不为空 可以返回给用户使用 // 这里移动fd指针 fd 是地址的地址 也就是移动后会将victim从链表中移除 if (SINGLE_THREAD_P) *fb = victim->fd; else REMOVE_FB (fb, pp, victim); if (__glibc_likely (victim != NULL)) { // 判断下尺寸对应的 fastbin 索引是否相等 size_t victim_idx = fastbin_index (chunksize (victim)); if (__builtin_expect (victim_idx != idx, 0)) malloc_printerr ("malloc(): memory corruption (fast)"); // 调试信息 check_remalloced_chunk (av, victim, nb); // 返回给用户的内存地址是从 void *p = chunk2mem (victim); // 调试信息 通过 memset 初始化p内存中值(perturb_byte ^ 0xff) alloc_perturb (p, bytes); return p; } } }
2.2 在 small bin 上查询合适的chunk 直接在 small bin 的链表中查找合适的 chunk,常用宏展开
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #define NSMALLBINS 64 #define SMALLBIN_WIDTH MALLOC_ALIGNMENT // 16 byte #define SMALLBIN_CORRECTION (MALLOC_ALIGNMENT > 2 * SIZE_SZ) // smallbin 最大值尺寸 64 * 16 #define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH) // 比较是否用户尺寸小于 smallbin 的最大尺寸 #define in_smallbin_range(sz) ((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE) //根据尺寸计算出对应索引 idx = sz / 16 #define smallbin_index(sz) ((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3)) + SMALLBIN_CORRECTION) // 以 p 为起始地址 向上偏移 s 长度内存 对其设置 属性 mchunk_size 的 prev_inuse #define set_inuse_bit_at_offset(p, s) (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size |= PREV_INUSE) #define PREV_INUSE 0x1 #define IS_MMAPPED 0x2 #define NON_MAIN_ARENA 0x4 #define set_non_main_arena(p) ((p)->mchunk_size |= NON_MAIN_ARENA)
small bin 中查找chunk的代码逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 // 用户请求的尺寸是否在 smallbin 的尺寸范围内 if (in_smallbin_range (nb)) { // 通过用户尺寸计算出 small bin 中对应尺寸的索引 idx idx = smallbin_index (nb); // 读取对应的bin bin = bin_at (av, idx); if ((victim = last (bin)) != bin) { // 不等于他自身说明bin 不是空的 可以使用 // 将 查询到的合适的chunk。victim 从 small bin 的链表中祛除 bck = victim->bk; if (__glibc_unlikely (bck->fd != victim)) malloc_printerr ("malloc(): smallbin double linked list corrupted"); // 设置下一个chunk的 prev_inuse set_inuse_bit_at_offset (victim, nb); bin->bk = bck; bck->fd = bin; // 若不是主线程 设置size底三位的 NON_MAIN_AREAN if (av != &main_arena) set_non_main_arena (victim); check_malloced_chunk (av, victim, nb); // 转换内存地址为用户地址 void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p; } }
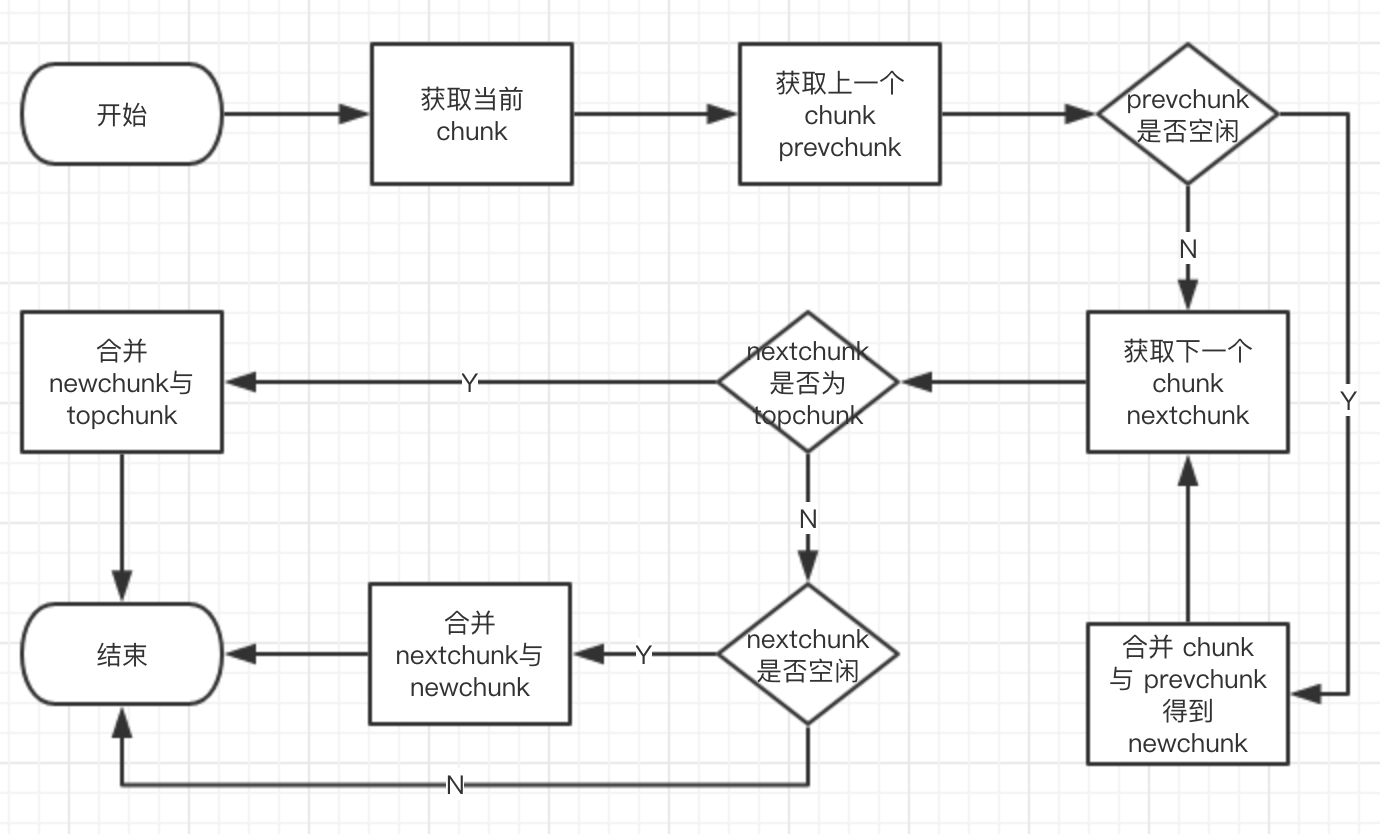
2.3 通过 consolidate 合并 空闲chunk 遍历整个fastbin,各个尺寸对应的链表。先查看上一个chunk 是否未使用,若未使用 将其从链表中移除,也就是与当前chunk合并(后续会通过size的形式实现)
整个合并逻辑是在循环中进行的 这样就会将相邻的空闲chunk 合并为一个 最后放入 unsorted bin 或者 top chunk 中提供给后续的内存申请 使用
常用宏:
1 2 3 4 5 6 7 8 9 10 11 12 13 // 获取chunk的真实尺寸 #define chunksize(p) (chunksize_nomask (p) & ~(SIZE_BITS)) // 将地址从 p 移动到 p+s #define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s))) // p指向的chunk的prev_inuse值,上一个chunk是否在使用中 #define prev_inuse(p) ((p)->mchunk_size & PREV_INUSE) // p指向的chunk的prev_size #define prev_size(p) ((p)->mchunk_prev_size) // p + s 指向的chunk 将其中的 标志位 prev_inuse 设置为 0 #define clear_inuse_bit_at_offset(p, s) (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE)) // p + s 指向的chunk 的 prev_inuse 的值 #define inuse_bit_at_offset(p, s) (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size & PREV_INUSE)
逻辑代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 static void malloc_consolidate(mstate av) { // fast bin 结尾 maxfb = &fastbin (av, NFASTBINS - 1); // fast bin 开头 fb = &fastbin (av, 0); do { // p = fb;fb = NULL; p = atomic_exchange_acq (fb, NULL); if (p == 0) continue; do { { unsigned int idx = fastbin_index (chunksize (p)); if ((&fastbin (av, idx)) != fb) malloc_printerr ("malloc_consolidate(): invalid chunk size"); } check_inuse_chunk(av, p); // 获取下一个chunk的地址与尺寸 nextp = p->fd; // next chunk ptr size = chunksize (p); nextchunk = chunk_at_offset(p, size); // next chunk ptr nextsize = chunksize(nextchunk); // next chunk size // 上一个chunk 没有被使用 是空闲的 if (!prev_inuse(p)) { // 移动指针 p 到上一个 chunk 的内存地址 prevsize = prev_size (p); size += prevsize; p = chunk_at_offset(p, -((long) prevsize)); if (__glibc_unlikely (chunksize(p) != prevsize)) malloc_printerr ("corrupted size vs. prev_size in fastbins"); // 将 p 从链表中取出 这时的p其实是 当前循环到的chunk 的上一个chunk prevchunk unlink(av, p, bck, fwd); } // 下一个chunk不是top if (nextchunk != av->top) { // nextinuse 是nextchunk 是否被使用 nextinuse = inuse_bit_at_offset(nextchunk, nextsize); // 若nextchunk未被使用 则将 nextchunk 从链表中取出 if (!nextinuse) { size += nextsize; unlink(av, nextchunk, bck, fwd); } // nextchunk 不是空闲的 则不合并,将其prev_inuse 设置为 0 else clear_inuse_bit_at_offset(nextchunk, 0); // 将切割下来的 p 加入到 unsorted bin 的列表头部 first_unsorted = unsorted_bin->fd; unsorted_bin->fd = p; first_unsorted->bk = p; if (!in_smallbin_range (size)) { p->fd_nextsize = NULL; p->bk_nextsize = NULL; } // 设置 prev_inuse 为 1 set_head(p, size | PREV_INUSE); p->bk = unsorted_bin; p->fd = first_unsorted; // 设置 size 这个size 其实是 prevchunk nextchunk 和chunksize 的和 以此实现 将这三个chunk合并的目的 合并后添加到了 unsorted bin 的头部 set_foot(p, size); } else { // 如果 p 的下一个 chunk 是 top 将 当前chunk与他的上一个chunk合并到top里 size += nextsize; set_head(p, size | PREV_INUSE); av->top = p; } } while ( (p = nextp) != 0); // 遍历链表 } while (fb++ != maxfb); // 遍历fastbin各个尺寸的chunk链表 移动fb指针 不到结尾则继续计算 }
将chunk从链表中移除的宏:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #define unlink(AV, P, BK, FD) { // 当前的尺寸与下一个chunk中 prev_size 尺寸不相等 if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0)) malloc_printerr ("corrupted size vs. prev_size"); // 将 p 从双向链表中移除 FD = P->fd; BK = P->bk; // 发现 fwd bck p 三者不连续 if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) malloc_printerr ("corrupted double-linked list"); else { FD->bk = BK; BK->fd = FD; // chunk是large bin 范围的 且 fd_nextsize 不空,说明 p 处在一个尺寸的 chunk 段中的最后一个 if (!in_smallbin_range (chunksize_nomask (P)) && __builtin_expect (P->fd_nextsize != NULL, 0)) { if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) || __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) malloc_printerr ("corrupted double-linked list (not small)"); // large bin 是双向链表 这里需要在 nextsize 的链表中也将其移除 if (FD->fd_nextsize == NULL) { if (P->fd_nextsize == P) FD->fd_nextsize = FD->bk_nextsize = FD; else { FD->fd_nextsize = P->fd_nextsize; FD->bk_nextsize = P->bk_nextsize; P->fd_nextsize->bk_nextsize = FD; P->bk_nextsize->fd_nextsize = FD; } } else { P->fd_nextsize->bk_nextsize = P->bk_nextsize; P->bk_nextsize->fd_nextsize = P->fd_nextsize; } } } }
下图是整个合并逻辑的流程图:
3 查询chunk 并对当前bin 中的chunk 做处理 这里是接着上一步 #2 的工作继续进行的,这里不会仅仅对链表上的chunk 做尺寸比较,还会对chunk 做切割、移动的操作。上一步合并chunk到 unsorted bin 、top chunk 的chunk 在这一步里就会用到了。
在unsorted bin 中查找 chunk
在largebin 中查找大于等于size的chunk进行切割处理
在所有的 bin 中查找大于等于size的chunk进行切割处理
切割 top chunk 返回合适的chunk
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 for (;; ) { int iters = 0; while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av)) { // unsorted bin } if (!in_smallbin_range (nb)) { // large bin } ++idx; bin = bin_at (av, idx); block = idx2block (idx); map = av->binmap[block]; bit = idx2bit (idx); for (;; ) { // all bins } use_top: // cut top chunk }
3.1 在 unsorted bin 上查询合适的chunk 循环 unsorted bin ,若unsorted bin的链表中只有一个 chunk 且这个chunk还是last_remainder 尺寸还合适 (size > nb + MINSIZE 这个条件的目的是方便切割 last_remainder)
然后就看下 unsorted bin 上面是否有正好满足尺寸的chunk 返回给用户 且要将这个chunk从链表中 移除
在然后就是将这些 chunk 根据尺寸合并到对应的 small bin 或 large bin 对应链表的头部,代码逻辑如下:
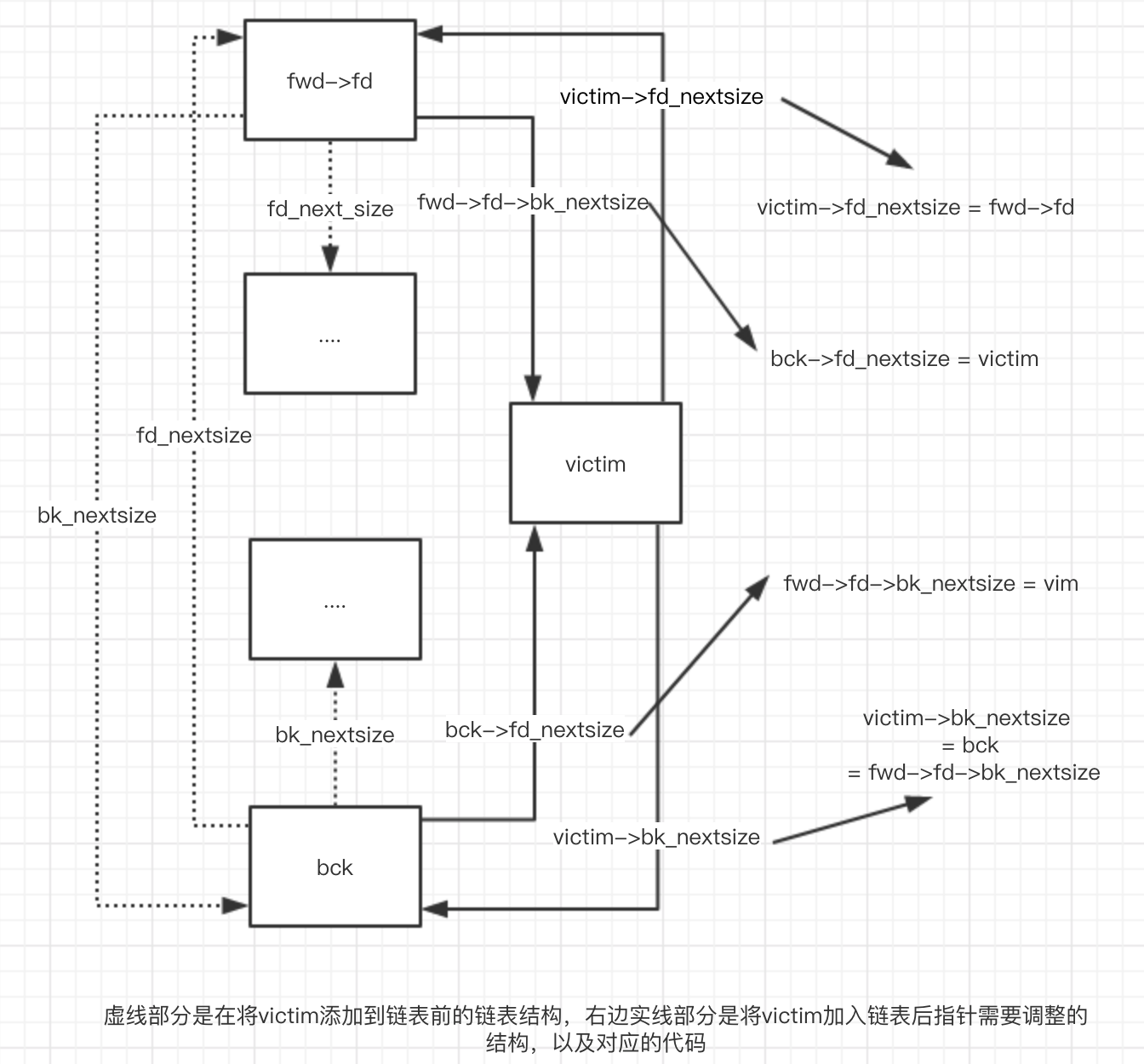
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 int iters = 0; // 遍历 unsorted bin 链表 ,unsorted bin 的循环是从链表底部开始的 // victim 会在下面代码中从列表中分割出去,以使这里的循环能够继续下去 while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av)) { // victim上一个chunk地址 bck = victim->bk; size = chunksize (victim); // victim 下一个chunk地址 mchunkptr next = chunk_at_offset (victim, size); if (__glibc_unlikely (size <= 2 * SIZE_SZ)|| __glibc_unlikely (size > av->system_mem)) malloc_printerr ("malloc(): invalid size (unsorted)"); if (__glibc_unlikely (chunksize_nomask (next) < 2 * SIZE_SZ) || __glibc_unlikely (chunksize_nomask (next) > av->system_mem)) malloc_printerr ("malloc(): invalid next size (unsorted)"); if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size)) malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)"); if (__glibc_unlikely (bck->fd != victim) || __glibc_unlikely (victim->fd != unsorted_chunks (av))) malloc_printerr ("malloc(): unsorted double linked list corrupted"); if (__glibc_unlikely (prev_inuse (next))) malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)"); // 尺寸在small bin的范围 且 victim是unsorted bin 链表中的第一个chunk 且 victim 是 last_remainder 且 victim的尺寸大于用户请求的尺寸 + chunk的最小尺寸(目的是方便切割victim) if (in_smallbin_range (nb) && bck == unsorted_chunks (av) && victim == av->last_remainder && (unsigned long) (size) > (unsigned long) (nb + MINSIZE)) { // 这里将 victim 分成两份 一份是用户请求的chunk 剩下一份是 remainder remainder_size = size - nb; // 剩下部分尺寸 remainder = chunk_at_offset (victim, nb); // 剩下部分内存地址 // 由于victim是 unsorted bin 链表中唯一一个chunk 这里将 unsorted bin 这个双向链表的 bk fd 全指向 remainder // 其实 这个操作也同时将victim 返回给用户的哪部分内存从链表中移除了 unsorted_chunks (av)->bk = unsorted_chunks (av)->fd = remainder; av->last_remainder = remainder; // 剩余部分赋值给 arena 的 last_remainder remainder->bk = remainder->fd = unsorted_chunks (av); if (!in_smallbin_range (remainder_size)) { // 如果剩余部分尺寸属于largin bin 需要将其内存中fd_nextsize bk_nextsize位置的数据清空 remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } // 设置 chunk 数据 set_head (victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head (remainder, remainder_size | PREV_INUSE); set_foot (remainder, remainder_size); check_malloced_chunk (av, victim, nb); // 将分割下来的用户部分返回给用户 void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p; } // 将victim从 unsorted bin 的链表中移除 // unsorted bin 这个链表是 栈结构 先进后出的 if (__glibc_unlikely (bck->fd != victim)) malloc_printerr ("malloc(): corrupted unsorted chunks 3"); unsorted_chunks (av)->bk = bck; bck->fd = unsorted_chunks (av); // 尺寸正合适 则可以直接返回给用户了 if (size == nb) { set_inuse_bit_at_offset (victim, size); if (av != &main_arena) set_non_main_arena (victim); check_malloced_chunk (av, victim, nb); void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p; } // 以下 将每次循环到的victim 重新分配到 small bin 或 large bin中 // 这里逻辑先计算一些指针 方便下面合并操作 // victim的尺寸在 small bin的范围内 if (in_smallbin_range (size)) { victim_index = smallbin_index (size); bck = bin_at (av, victim_index); fwd = bck->fd; } // victim的尺寸在 large bin的范围内 // 这里主要是需要先处理large bin 中的 nextsize 链表 else { victim_index = largebin_index (size); bck = bin_at (av, victim_index); fwd = bck->fd; if (fwd != bck) { // large bin 对应尺寸的链表不空 size |= PREV_INUSE; assert (chunk_main_arena (bck->bk)); // 如果 victim尺寸比large bin 链表中最后一个chunk尺寸还小 (large bin 链表中的chunk按照从大到下 排列) // 则可以将 victim 直接添加到 最后一个chunk的后面 这里只处理了 nextsize 链表 fd bk 的链表需要在下面统一处理 if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk)) { fwd = bck; // 第一个chunk bck = bck->bk; // 最后一个chunk victim->fd_nextsize = fwd->fd; // victim放在最后 形成 循环链表 他的fd 就是 fwd victim->bk_nextsize = fwd->fd->bk_nextsize; // fwd->fd->bk_nextsize 的当前值就是 bck fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; } else { assert (chunk_main_arena (fwd)); // 循环查询 直到size >= nextsize 段的尺寸 while ((unsigned long) size < chunksize_nomask (fwd)) { fwd = fwd->fd_nextsize; assert (chunk_main_arena (fwd)); } // 尺寸相等并没有处理 nextsize链表,因为这不是必须的,既然相等 那我们不要将其放在 相同尺寸链表中的头部就好了,这样不会影响 nextsize链表 // 此时只需要将fwd向下移动 然后将 bck 设置到之前fwd的位置 victim就会插入 few 与 bck 之间 ,victim的位置不会是在头部 这样就不影响 nextsize链表 if ((unsigned long) size == (unsigned long) chunksize_nomask (fwd)) fwd = fwd->fd; else { // 此时victim尺寸是不与当前链表nextsize中的任何尺寸相等的,将victim添加到 fwd的上面 victim->fd_nextsize = fwd; victim->bk_nextsize = fwd->bk_nextsize; fwd->bk_nextsize = victim; victim->bk_nextsize->fd_nextsize = victim; } bck = fwd->bk; // 便于下面逻辑处理 } } // 链表为空 victim 是这个链表的唯一一个chunk 所以 nextsize链表中的 fd bk 都指向自己 else victim->fd_nextsize = victim->bk_nextsize = victim; } mark_bin (av, victim_index); // 将victim添加到主链表中 victim->bk = bck; victim->fd = fwd; fwd->bk = victim; bck->fd = victim; // 考虑到性能 尝试不超过 10000 次 #define MAX_ITERS 10000 if (++iters >= MAX_ITERS) break; }
这里有一部分代码需要分析下,当尺寸范围属于 large bin的时候 需要做一些额外的处理,因为 large bin的链表中的chunk尺寸并不相等,他们根据尺寸从大到小排列,为了便于搜索 large bin 的每个链表又维护了一个nextsize链表(fb_nextsize bk_nextsize)
若victim的尺寸并不是最小的,则需要遍历nextsize链表 while ((unsigned long) size < chunksize_nomask (fwd)) {fwd = fwd->fd_nextsize;} 查找到合适的 fwd ,这个时候需要先判断尺寸是否相等 这种情况 如果将victim添加进链表 但是不添加到 一段相同尺寸chunk的头部 就不需要调整 nextsize 链表 ,nextsize链表中的 fd_nextsize bk_nextsize 存储的地址是 一段相同尺寸链的头部和尾部 chunk 所以有代码 if ((unsigned long) size == (unsigned long) chunksize_nomask (fwd)) fwd = fwd->fd;
其他情况的指针移动则相对简单了,通过 fwd 的地址 将 victim 的 nextsize 指针添加进 fwd 与 fwd->bk 之间。
3.2 large bin 查询 这段主要是在large bin中循环查询,这个查询是倒叙的,查找到正好大于或等于 nb 的chunk 然后对其切割。切割的一部分返回给用户 另一部分remainder 添加到 unsorted bin 链表里,若剩余部分尺寸不够一个chunk最小尺寸 (MIN_SIZE) 则不进行切割 整个返回给用户
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 if (!in_smallbin_range (nb)) { bin = bin_at (av, idx); // 在large bin 的链表中取第一个chunk 若这个chunk 不为头节点 则说明链表不空 // 且第一个chunk的尺寸要大于等于请求尺寸 因为第一个chunk是这个链表最大的chunk 若不然 这个链表中的所有chunk都不能满足条件 if ((victim = first (bin)) != bin && (unsigned long) chunksize_nomask (victim) >= (unsigned long) (nb)) { // 倒序 先从最小的 chunk开始 victim = victim->bk_nextsize; // 循环 直到找到 victim 正好大于等于 nb 的 chunk段 while (((unsigned long) (size = chunksize (victim)) < (unsigned long) (nb))) victim = victim->bk_nextsize; /* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ // 若不是最后一个chunk 且 victim的下一个chunk尺寸与victim相等 则将victim指针移动到下一个 // 这里的目的是避免用到第一个chunk 这样会破坏 nextsize链表 多出来重建链表的代码 if (victim != last (bin) && chunksize_nomask (victim) == chunksize_nomask (victim->fd)) victim = victim->fd; // 这里 切割victim的代码单独抽离出来了 看下面 } }
victim的切割
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 // 多余的尺寸 remainder_size = size - nb; // 将victim从链表中移除 unlink (av, victim, bck, fwd); // 剩下部分不够一个最小chunk 则不用切割 整个返回给用户 if (remainder_size < MINSIZE) { set_inuse_bit_at_offset (victim, size); if (av != &main_arena) set_non_main_arena (victim); } else { // 切割 victim // 剩余chunk部分的地址 remainder = chunk_at_offset (victim, nb); /* We cannot assume the unsorted list is empty and therefore have to perform a complete insert here. */ // 将剩余部分添加到 unsorted bin 中 bck = unsorted_chunks (av); fwd = bck->fd; if (__glibc_unlikely (fwd->bk != bck)) malloc_printerr ("malloc(): corrupted unsorted chunks"); remainder->bk = bck; remainder->fd = fwd; bck->fd = remainder; fwd->bk = remainder; if (!in_smallbin_range (remainder_size)) { // 若剩余部分属于 large bin 初始化 nextsize链表指针 remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } // 设置信息 set_head (victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head (remainder, remainder_size | PREV_INUSE); set_foot (remainder, remainder_size); } check_malloced_chunk (av, victim, nb); // 返回给用户 void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p;
3.3 bins 查询 当上面的过程都没有找到合适的chunk,这里会遍历整个bins查找合适的chunk,查找bins链表中存在的chunk 正好大于用户请求尺寸的chunk 然后对其切割返回。这里涉及到的操作分为两部分 1. bins 链表的查询 2. 切割chunk,其中切割chunk部分的代码跟上一步large bin 的切割是一样的逻辑
1 2 3 4 5 6 7 8 9 10 11 12 // ...... remainder->bk = bck; remainder->fd = fwd; bck->fd = remainder; fwd->bk = remainder; // 若用户请求尺寸是在 small bin 的范围内 这时将 remainder 的地址会赋值给 arena 的 last_remainder if (in_smallbin_range (nb)) av->last_remainder = remainder; if (!in_smallbin_range (remainder_size)) { remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } // ......
这里主要需要理解的代码是在查找上,这里使用 bitmap 算法来加快查询。arena结构中有一个属性 unsigned int bitmap[4] 用来表示 bitmap ,其分为4个数组 也就对应 bitmap 的四个段 ,每个段是一个 unsigned int int 需要4个字节 每个字节有8个bit,也就是 bitmap 每个段的长度是 8 * 4 = 32 bit。bitmap总共拥有的 bit 是 32 * 4 = 128 个 这也正对应arena 中的 bins,每个bin是一个chunk链表头部,bit 位用 1 表示 这个链表不空 0 表示链表为空,这样在查询的时候可以直接跳过了,以此实现加速查询,相关的宏如下:
1 2 3 4 5 6 #define NBINS 128 #define BINMAPSHIFT 5 #define BITSPERMAP (1U << BINMAPSHIFT) // 2^5 = 32 #define BINMAPSIZE (NBINS / BITSPERMAP) // 128 / 32 = 4 // 计算 bin 中索引对应的bitmap段 也就是 block #define idx2block(i) ((i) >> BINMAPSHIFT) // i / 32
还有一个相对要分析下 #define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT) - 1)))) ,可以将其拆分成两部分 1U << [express] 和[express]部分 i & ((1U << BINMAPSHIFT)-1) 。 [express] 部分其实就是相对于一个段对应bit的偏移量,然后 增加 1U << [express] 就是偏移量的一种表示 方便下面代码的计算, 比如 偏移量 offset 是 7 则对应的变量bit的值就是 00000000 00000000 00000000 01000000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 ++idx; bin = bin_at (av, idx); block = idx2block (idx); map = av->binmap[block]; bit = idx2bit (idx); for (;; ) { // 若 bit > map 说明当前block中没有合适的链表 // bit 是以 32bit 中的一位为1表示偏移量 map 是整个block的bin链表的使用情况 // bit > map 说明 bit所在的高位对应到 map 一定为 0 ,则这个block 一定没有合适的链表 if (bit > map || bit == 0) { do { // 超出 bitmap 范围说明遍历的整个bins 链表都是空的 则直接到 use_top的逻辑 if (++block >= BINMAPSIZE) goto use_top; } while ((map = av->binmap[block]) == 0); // 若整个bitmap的block都为0 说明整个block中的bin链表都是空的 需要向后再次查询 // 取出block中第一个 bin bin = bin_at (av, (block << BINMAPSHIFT)); bit = 1; } // 这里一定会找到bin 整个block为空的情况 上一步操作会过滤掉 全为空的情况在上面就会 goto user_top; // 这里其实循环遍历的是一个block的bin while ((bit & map) == 0) { // bit 对应位置链表为空 // 向后遍历更大尺寸的 bin 同时移动bit位置 bin = next_bin (bin); bit <<= 1; assert (bit != 0); } // 读取 bin 链表中的最后一个chunk victim = last (bin); // 若当前的bin 链表还是空的 bitmap的数据有误 if (victim == bin) { // 修复 bitmap的数据 av->binmap[block] = map &= ~bit; /* Write through */ // 到下一个bin bin = next_bin (bin); bit <<= 1; } else { // victim 切割 } }
若 bit == 0 或 bit > map 则以段的形式遍历整个bin 如果整个bin链表都是空的 (av->binmap[block] == 0) 则直接执行 use_top 的代码,若在向后遍历的过程中找到了合适的 block 段 则取出block开始的 bin 并 将bit设置为对应bin的位置(bit = 1) 其中 bit > map 说明当前block中肯定找不到尺寸大于nb且bin链表不为空的链表了。while((bit & map) == 0) {....} ,bit & map 说明bin为空链表 则 向后遍历 bin 这个循环过程是一定会找到合适的bin的。(victim = last(bin)) == bin ,若为空 说明 bitmap 中对应的数据不准确 这时又对这个bitmap中的bit位的值做修复处理 av-bitmap[block] = map & ~ bit 继续向后移动 bin
找到合适的bin后 就做切割处理 这段的代码逻辑和 large bin 中的处理是一样的。
4 切割 top chunk 这一步通过对 top chunk 的切割来分配内存,若不够切割则通过函数 sysmalloc 分配新的 heap_info
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 // 获取top chunk的其实地址 victim = av->top; size = chunksize (victim); if (__glibc_unlikely (size > av->system_mem)) malloc_printerr ("malloc(): corrupted top size"); // top chunk 的尺寸足够用来切割 if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE)) { // 切割top chunk 剩余部分作为新的 top chunk remainder_size = size - nb; remainder = chunk_at_offset (victim, nb); av->top = remainder; // 返回用户申请部分的chunk set_head (victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head (remainder, remainder_size | PREV_INUSE); check_malloced_chunk (av, victim, nb); void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p; } /* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ // 还存在 fast bin else if (atomic_load_relaxed (&av->have_fastchunks)) { // 合并fastbin中的chunks malloc_consolidate (av); /* restore original bin index */ if (in_smallbin_range (nb)) idx = smallbin_index (nb); else idx = largebin_index (nb); } /* Otherwise, relay to handle system-dependent cases */ else { // top chunk 不够分配的话 调用函数 sysmalloc 增长 arena 的 heap_info void *p = sysmalloc (nb, av); if (p != NULL) alloc_perturb (p, bytes); return p; }